
Meta's Open Source AI Ambitions
Is Llama the Android of LLMs?


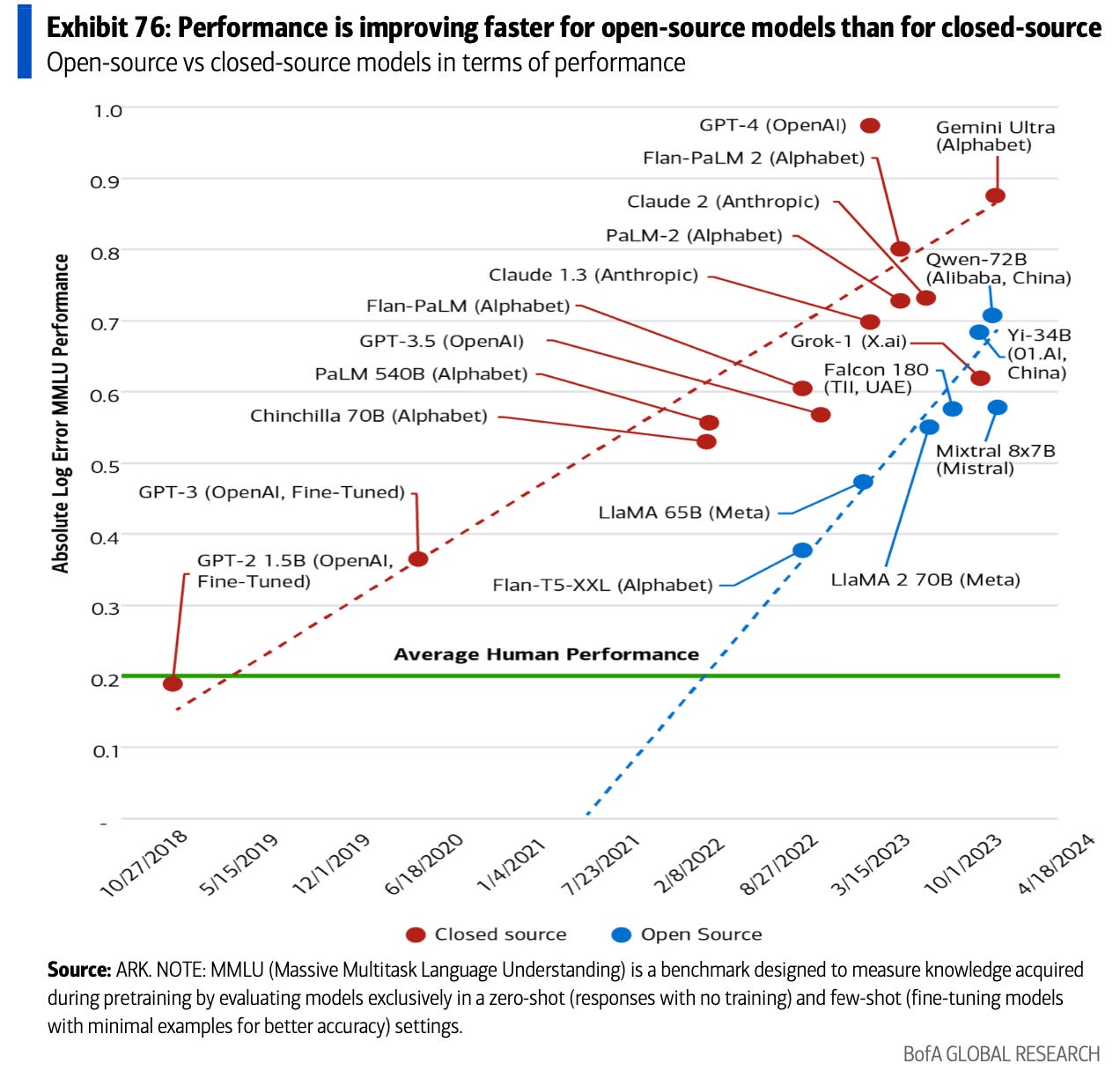
Last week, Meta released their latest set of Large Language Models – Llama 3. We continue to see that the combination of larger training datasets, more compute, and new AI research yield better models. The early data below suggests Llama 3 is the best open source model available, trailing only OpenAI’s GPT-4.
>> A quick definition – Open Source models enable others to view and use the IP associated with the model. Meta’s specific license for Llama allows free commercial usage for companies with less than 700 million monthly users (>99.9% of companies).

To put this in perspective, Llama 3 is better than AI models from multiple billion dollar companies whose entire business is predicated on selling models-as-a-service (Anthropic, Cohere, etc). Unlike those companies, Meta allows for free commercial use of these models for nearly everyone1.
The obvious question here is why is Meta spending so much money on building these models just to give them away for free? You would think that a company that came out of a self-proclaimed year of efficiency would not enter such a capital-intensive technology arms race.
Zuckerberg’s recent interview illuminated just how consequential AI could become to Meta and how they’re trying to steer its direction.
Before getting into why Meta is all in on open source AI, let’s consider why they were better positioned than most.
Talent + Compute = AI
To build powerful models, you primarily need two ingredients:
AI talent (Engineering and Research)
GPUs for compute
Meta was uniquely positioned in that they ended up with these two ingredients prior to their ambitions of building LLMs.
They’ve had the AI talent for years. The core of their product is AI-powered content feeds and ads and their AI research group is now ~10 years old.
How they acquired the GPUs is more interesting. Mark describes that Meta acquired the GPUs initially to support Instagram Reels.
We got into this position with Reels where we needed more GPUs to train the models. It was this big evolution for our services. Instead of just ranking content from people or pages you follow, we made this big push to start recommending what we call unconnected content, content from people or pages that you're not following.
As Reels tried to do its best impersonation of TikTok’s For You page, Meta acquired GPUs to train and serve these recommendation models. So even though Instagram Reels was late to the For You Page, they were early enough to GPUs.
Applications vs. Models
Undoubtedly, Meta was well-positioned to get into the LLM game. But why did they? And why did they choose open source? The answer comes down to controlling their value chain by undermining new entrants.
Like the rest of the industry, Zuckerberg seems to believe that AI and LLMs specifically will yield better products. But they also have the potential to disrupt Meta’s value chain. In that way, this AI shift is similar to the shift to cloud or mobile where new technology architectures and distribution models emerged. While mobile was an overall win for Meta, Zuckerberg describes that it also introduced economic challenges (app store commission) and loss of control (app store approval, user data collection limitations).
So the question is, are we set up for a world like that with AI? You're going to get a handful of companies that run these closed models that are going to be in control of the APIs and therefore able to tell you what you can build?
AI is here to stay, so Meta is attempting to steer its trajectory to one that is more favorable for them long-term. For the sake of simplicity, we can think of AI as playing out in one of two scenarios.
Scenario 1 — value accrues to the models2
For this to be true, you have to believe that models end up being highly differentiated and having high switching costs. This is what the OpenAIs and Anthropics of the world are hoping for. The analogy here would be that Foundation Models are the new cloud providers.Scenario 2 — value accrues to the applications
For this to be true, you have to believe that models end up being commoditized and easily substitutable for one another. This is what Meta is hoping for because they are first and foremost an application company.
Because Meta’s core assets are its applications, it would prefer scenario 2. In fact, if Meta is unable to add the best AI to its apps, then it may be at the mercy of a specialized model provider like OpenAI. Or worse yet, they could lose users to a new app with better AI. To some degree, these things are already happening with ChatGPT and Character.ai acquiring consumer attention more rapidly than we’ve seen before. Ultimately, Meta has to figure out AI because they have too much to lose.
Why Open Source AI
Meta’s free, open-source approach is their best bet to make scenario 2 happen. They hope to commoditize the model layer, preventing new players from gaining disproportionate control. And the best way to commoditize models is to make it easily accessible and free.
This goes back to two of the primary benefits of open source:
Ease of adoption (anyone can access, free, independent of all other products)
Community-driven ecosystem (customizable, compatibility with other tools)
I think there are lots of cases where if this [LLMs/AI] ends up being like our databases or caching systems or architecture, we'll get valuable contributions from the community that will make our stuff better.
Together, Meta creates a flywheel where developers use Llama because it’s accessible, which in turn drives a better ecosystem, which in turn attracts more developers. For Meta, this flywheel should result in better AI powering their applications without relying on a single, overly powerful model provider.
The Android of Models
The analogy that comes to mind is that OpenAI is trying to build iOS and Meta is trying to build Android3. While OpenAI builds proprietary, closed models, Meta is building free, open source models for everyone else. As much power as Apple has in the mobile market, the alternative that Android provides is an important balancing force.
In many respects, Meta’s decisions here are a reflection of the past. It is taking steps to avoid another Apple in its value chain or the rise of another TikTok. While their pursuits are in self-interest, I am personally optimistic about what open source AI means for the tech landscape. More open models should enable a richer application and infrastructure landscape. In this case, I think there is incentive alignment between Meta’s AI ambitions and the future AI landscape.
It’s still early, but the signs suggest that open source is catching up fast!
DMs open » nandu
nearly everyone in this case meaning everyone with less than 700m monthly users (sorry Snapchat, Linkedin, Tiktok, etc)
Zuck did note that if cloud providers are reselling their models at scale, Meta would take some revenue share
ironically, Google is not as incentivized to build the Android of models given that their core business is Search. so far, it seems that they want to maintain their Search advantage with proprietary AI models like Gemini.
You didn't mention data at all in this post