
Infrastructure after AI Scaling
why AI scaling won't last forever (and what comes next)

Despite the countless new AI infrastructure startups, Nvidia and OpenAI have swallowed up the lion’s share of value across the AI infrastructure stack:
Nvidia’s data center revenue grew 427% YoY, with over 60% EBITDA margins. The demand for Nvidia’s market-leading GPUs hasn’t slowed because they are one of the core ingredients to training AI models. To put this growth into perspective, Zoom grew 355% one year after the world launched into a pandemic — while only being <5% of the revenue scale that Nvidia is at.
OpenAI is the second biggest beneficiary, with recent reports claiming the business grew to a $3.4B revenue run rate, up from $1.6B late last year. OpenAI is continuing to invest in building better models and maintaining their market lead.
The disproportionate success of these two players can be largely attributed to AI scaling laws, which offer a rough blueprint of how to improve model performance. Since foundation model providers win customers on the basis of model performance, they will continue to build better models until there’s no more juice left to squeeze. At that point, I believe the broader AI infrastructure ecosystem will flourish. AI application builders move from the experimentation phase to the optimization phase, opening up new opportunities for infrastructure tooling.

Nvidia and OpenAI love AI scaling laws
AI scaling laws show that model performance improvement is driven by 3 main factors:
Language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute. We expect that larger language models will perform better and be more sample efficient than current models. — Scaling Laws of Neural Language Models (January 2020)

This insight has been the bedrock of improvements in foundation models over the past few years. It’s the reason to push towards bigger and bigger models.
The best way to make money on this scaling law equation has been to either provide one of the inputs (like Nvidia) or combine the inputs yourself (like OpenAI).

Because models are improving so fast, the rest of the infrastructure stack cannot stabilize around them. Other AI infrastructure startups address the limitations of models themselves, and therefore, their adoption may be slower during this AI scaling period1.
Why AI scaling breaks
Surely, this can’t continue forever (~cautiously optimistic NVDA holder~). At some point, either 1) these laws no longer apply or 2) we can no longer scale up one of the inputs.
The first reason AI scaling would break is that increasing these 3 inputs no longer results in a meaningful improvement in model performance — the operative word is “meaningful”.
Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. What matters is “emergent abilities”, that is, models’ tendency to acquire new capabilities as size increases. — AI Snake Oil
We want models to develop new abilities for new use cases. This makes the R&D economics here unlike most other technologies. We don’t build better cars hoping that they will also learn to fly, but that’s the magic we’re hoping for with foundation models. And to be very clear, the AI scaling laws tell us that we’ll keep getting better at predicting the next token, but they do not have any predictive power on if and when we get new emergent abilities.
Okay, but even if we continue to see AI scaling laws hold, we may hit a bottleneck on one of the inputs. In other words, we may no longer be able to scale either model size, training data, or compute. The most credible hypotheses I’ve seen are related to constraints around data and hardware limitations.
Data Limitations
On the data side, it’s simple — we may just run out of training data.
Epoch has estimated that there are ~300T tokens of publicly available high-quality text data. Their estimates suggest that we will run out sometime late into this decade. We know that Llama-3 (the best available open source model) was trained on a 15T token training set of publicly available sources. As shown below, models have historically increased dataset size by 2.8x per year, so in ~5 years we will need >100x our current amount. Even with innovative AI techniques and workarounds, depletion of our training data seems inevitable.

Hardware Limitations
Another possibility is that we are unable to scale model size and compute due to hardware limitations, which could take two forms. First, GPUs’ memory and bandwidth capacity may not keep up with the demands of increasingly larger models. Sustaining the current pace of progress requires ongoing innovation in hardware and algorithms.
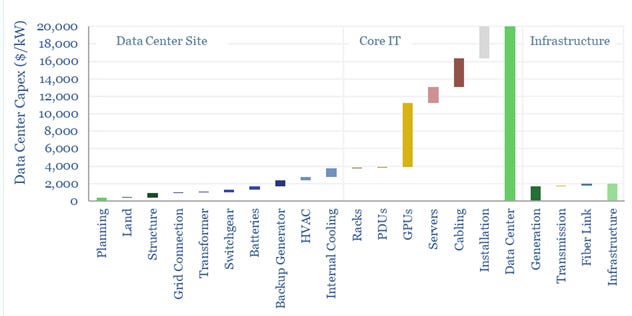
Outside of the GPU, there are a lot of novel supply chain, energy, and networking problems associated with scaling up data centers. Meta had to scrap their previously planned data center buildout because they thought, “if we're just starting on construction for that data center, by the time we're done, we might be obsolete [unless we futureproof].” As hard as acquiring GPUs is today, building future-proof data centers is harder.
Infra in a post-AI scaling world
As AI scaling hits its limits, the constraints on model size, data availability, and hardware capabilities will usher in a new infrastructure landscape. Nvidia’s growth will slow down and OpenAI will hope to solidify their position as the AWS of AI. The diminishing returns of larger models will necessitate a shift in focus towards optimizing existing resources and away from the foundation model layer of the stack.
I’m excited for new categories of infrastructure to emerge as companies shift from experimentation to optimization. The following are themes I’m interested in:

1/ SMALL MODELS
The problem with very large models is that you’re carrying the cost of everything that it does for a very particular purpose… Why do you want to carry the cost of this giant model that takes 32 GPUs to serve for one task?
— Naveen Rao, CEO MosaicML
There are multiple reasons to run small models. One group of reasons focuses on resource-constrained environments where calling a large cloud-hosted model is not feasible. There has been interesting research focused on optimizing model architecture under the constraints of model size for mobile in particular. Beyond research, companies like Edge Impulse2 help build and deploy models on power-constrained devices ranging from wearables to IoT.
Even when you can run large models, it may not be preferable. Smaller models are cheaper (inference cost) and faster (latency). As AI scaling slows down, companies will shift from experimenting with new AI use cases to scrutinizing the cost/performance of the ones they have deployed. There has been a lot of work around quantization and distillation, but these techniques can still be challenging to implement for very large models.
2/ FINE-TUNING
Today, fine-tuning has fallen out of favor for many app builders. Fine-tuning is considered expensive, time-consuming, and more challenging to adopt than techniques like prompt engineering or basic RAG. For many companies, staying up-to-date with the latest model improvements is more important than the incremental boost from fine-tuning.
While the research community has introduced innovations like LoRA and prefix tuning, implementing these fine-tuning methods remains non-trivial for the average product team. Companies like Predibase and Smol aim to lower the barrier to fine-tuning while enabling teams to build task and domain-specific models.
3/ MULTI-MODEL SYSTEMS
Instead of using the most powerful and expensive model for every query, enterprises are building multi-model systems. The idea is to break complex queries into smaller chunks that can be handled by task-optimized smaller models. Companies like Martian, NotDiamond or RouteLLM focus on the model routing for AI developers. Alternatively, businesses like Fireworks are building these “compound AI” systems themselves and letting end developers use them for inference.
Companies like Arcee and Sakana are charting course for a different multi-model future. They are leveraging model merging as a means to create new models altogether. The former is pushing a paradigm where you merge a small domain-specific model with a large base model, while the latter is focused on merging many smaller models focused on narrow domains or tasks.
4/ DATA CURATION
If we run out of data, companies will have to compete on data quality and curation rather than sheer quantity. Because more data typically results in better models, companies like Scale AI are seeing lots of traction today in providing labeling and annotation services to scale data volume.
Eventually, we think the opportunity will shift towards more deeply understanding the relationship between training data and model outputs. Companies like Cleanlab and Datology help answer questions like which datasets are most valuable for a specific task, where are gaps or redundancies, how should we sequence training data, etc.
As synthetic data becomes a more important part of training datasets, there has been interesting research tying synthetic data towards specific model objectives. Because data has so much variability, more vertically-focused solutions may be necessary for niches like healthcare or financial services.
Closing
Timing is critical for startups. The right combination of market and technology catalysts are necessary to scale against the tide of incumbent solutions. AI scaling laws have proven to be the backbone of growth for both Nvidia and OpenAI. I’d argue that the inevitable slowdown of AI scaling will actually be the “why now” for a new wave of infrastructure startups.
As the industry transitions from a focus on sheer scale to optimizing and innovating within existing constraints, the companies that can navigate and lead in this next phase are being built today. If you’re building or thinking about AI infrastructure for a post-scaling world, I’d love to chat.
Nandu
twitter: @nanduanilal
email: nanilal@canaan.com
the two other infra categories that I think have significant revenue are AI inference and GPU clouds, both of which are very tightly coupled to the GPU and model layers
Edge Impulse is a Canaan portfolio company