
The State of NLP & LLMs
An overview of the market today and opportunities ahead in the large language model era of NLP


There are lots of interesting, fundable software businesses out there, but very few make you feel like you’ve been catapulted into the future. But the advances in Natural Language Processing (NLP) are easily some of the most surprising and awesome that I’ve seen in my time in venture. As proof, I offer you a handful of examples that I think are very cool:
At a very high-level, NLP is a branch of AI that deals with our ability to interact with computers via human language. There are a number of problems or tasks within the NLP umbrella including:
Question-answering
Machine translation
Summarization
Sentiment analysis
Intent recognition
Language generation
These problems are not entirely new either. We have been trying to solve translation for decades from IBM in 1954 to Google Translate launching in 2006. However, things have massively changed in the past 5 years. Breakthroughs in model architecture have brought performance, costs, and versatility to a level where the technology is far more accessible and applicable than ever before.
WHERE WE STARTED
Until 2017, the state-of-the-art architecture for natural language models was the recurrent neural network (RNN) and variations of it. The way in which the architecture sequentially processes inputs resulted in a couple of major drawbacks to the approach:
Difficult to train – Because RNNs process data sequentially, it is difficult to parallelize training. So training these models took a long time since you wouldn’t easily be able to split it across a ton of compute resources. In practice, this limits the amount of training data you could realistically train your models on.
Difficult to understand longer text sequences – RNNs also had a tough time understanding longer text sequences. An overly simplified way to describe it is that if you provided a large training input, it would essentially “forget” the words much earlier in the sentence by the time it was processing the words at the end. Consequently, these models were not so great at processing longer, complex pieces of language. This is one of the reasons that the use cases for NLP had gravitated toward shorter, isolated text interactions (ie chatbots).
ENTER TRANSFORMERS
In 2017, Google Brain and UToronto researchers proposed a new architecture that addressed these two drawbacks with the introduction of Transformers.
Unlike RNNs, the Transformer architecture processed information simultaneously rather than sequentially. This unlocked parallel computation for training, which meant you could use a bunch of GPUs to accelerate model training times. The Transformer removed much of the training bottleneck that existed previously, allowing for much larger training datasets.
Secondly, the Transformer introduced the idea of self-attention to determine what a word meant in the context of the other words around it. Put another way, for any given word in a sentence, it is asking itself what are the other words that I should be paying attention to? With enough training data, it is able to build an understanding of how different words are connected to each other. After this paper in 2017, there have been a number of landmark models that have been developed like ELMo, GPT, BERT. Today we have various versions of these models at various sizes, specialties, or domain-specificity. One non-obvious note here is that many of these state-of-the-art models are open-sourced which allows the NLP community to collaborate rather than compete purely in silos.
WHY NOW?
Now that these models have been out in the wild for a few years, I think there are a few reasons why now is a really interesting time for NLP.
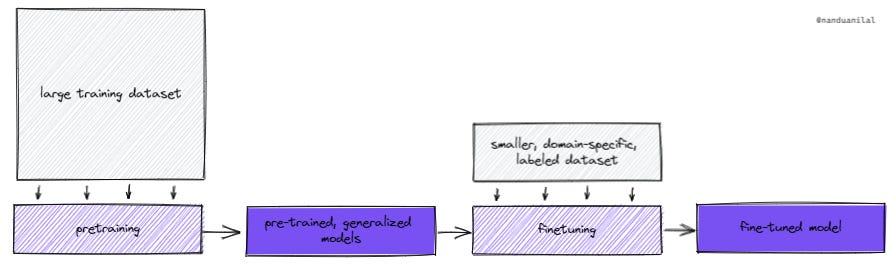
Pre-trained Large Language Models (LLM) → Historically, language models needed to be purpose-built for a specific use case given the challenges associated with training mentioned earlier. As a result, models were trained for specific problems, but could not easily expand to solve new problems. This made it challenging for new startups to leverage state-of-the-art as they were forced to start from scratch when it came to collecting data and model-building. Today, state-of-the-art models are large, pre-trained, generalized models which perform well across problem types and domains. In other words, more of the training is done upfront, making them more accessible to less resourced teams. These pre-trained models can be fine-tuned with an additional labeled dataset to solve specific problems more effectively. I think this paradigm of model-building is far more conducive to new startup creation.
Parity with humans on multiple benchmarks → We’ve reached the point where there is minimal-to-zero compromise on quality by outsourcing tasks to machines. In fact, in areas like multi-sentence reading comprehension, state-of-the-art models outperform human baselines (for more info on benchmarks). In fact, major AI benchmarks like Squad are being updated as models continue to beat human baseline as shown below.
Hardware improvements -> As Nvidia continues to push the frontier on the hardware side, AI training time and inference latency is decreasing. The speed at which these models have grown in size is exponential. While the original GPT had ~100 million parameters, GPT-4 is expected to have ~100 trillion parameters. These larger models are only made possible by hardware providers delivering orders of magnitude improvements as well.



THE COMMERCIAL OPPORTUNITY
Shifting from the technology side to the commercial opportunity, we’re seeing businesses transition their workflows and data from physical to digital. As a result, data is being created faster than we can digest it. NLP fills this void by essentially giving machines the ability to read and write like humans, but with speed and scalability. This manifests in a few different value propositions that I would categorize into the following three buckets:
Automation – The most straightforward advantage of giving machines human-like abilities is that you can automate expensive human labor. Instead of having teams manually read documents or text, automation-focused companies can leverage NLP to “read” and have software take some appropriate action. As an example, an investment firm may want to pull everything a public company has said about churned customers over the past 5 years. Instead of sifting through years of interviews and earnings calls, models could identify mentions of phrases that refer to “churn” or similar terms. Companies providing this value proposition are making the argument that instead of paying a team $500k to accomplish these types of activities, pay $100k to do it faster with software.
Intelligence – I am also seeing businesses go beyond automating human workflows and becoming broader intelligence engines. As humans, our ability to digest and analyze information starts to dip when we are dealing with a high volume of information. Consider a business like DoorDash that receives thousands of feedback tickets per day through chat messages. No one person could glean any insight from all that qualitative data, but NLP can analyze this information quickly and identify clusters of problem areas or trends in real-time. By providing an intelligence layer over large amounts of information, employees can readily identify trends and query information. Companies providing this value proposition are making the argument that they can surface the right insights to you such that you can make more effective revenue-driving or cost-cutting decisions.
Generation – Another frontier that is being pushed today is around language generation. In addition to understanding what humans are saying, language models have significantly improved in generating new content. This technology can help generate SEO-ready blog posts, sales outbound emails, or easy-to-digest summaries of legal documents. While the value proposition here certainly overlaps with automation, it is unique in that generation is far more subjective and therefore will likely rely on some level of human review. Companies in this category are typically making the argument that you can supercharge the productivity of an existing team to create better and more content.
LANDSCAPE
While the above section outlined a few of the value propositions that companies in the space can provide, companies tend to position themselves slightly differently in the market. At the application-level, I see companies position around a specific vertical, functional area, or language problem. On the infrastructure side, companies typically focus on model training, building, or deployment. Below is a representation of the various types of companies building, leveraging, or enabling NLP.
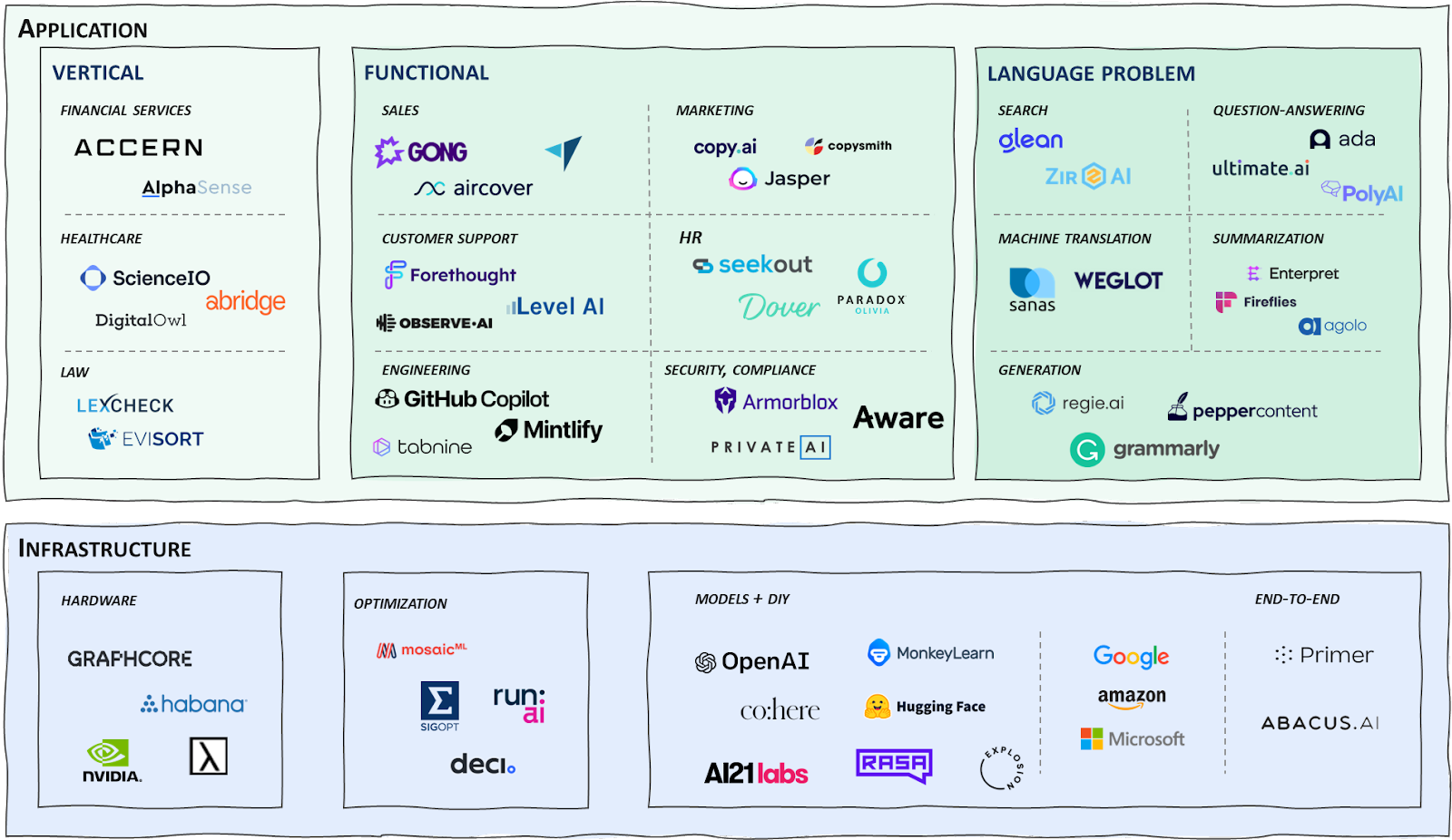
We can segment the landscape a few different ways:
Vertical: Industries with their own unique documents, language, vocabulary, etc will likely warrant their own software solutions. Popular large language models like BERT already have vertical-specific variants like ClinicalBERT (healthcare) or FinBERT (financial services). Financial services, healthcare, and legal seem like early markets given the amount of domain-specific language data available, but I anticipate we’ll see more industries with dedicated solutions.
Function: Most of the NLP-based companies today seem to orient around a specific job function like sales or support. What’s compelling here is that there’s an opportunity to build deeper into a workflow rather than just providing the language processing layer. The players in the space today are a combination of businesses that have been leveraging large language models from the beginning or are just experimenting with them for their existing products.
Language problem: There are also a number of companies that have oriented more around a specific type of language problem rather than a specific vertical or business function. For example, companies focused on translation would be valuable to any customer-facing team, rather than focusing solely on just one. Companies focused on enterprise search similarly span an entire organization.
Infrastructure: Perhaps the area generating the most buzz thus far has been on the infrastructure side. On the model side, OpenAI and Cohere are building and monetizing proprietary models/APIs while Hugging Face has focused on making models broadly accessible. Big tech plays a significant role here both with their open source model contributions and paid API products. Hardware companies like Nvidia continue to improve their deep learning-optimized GPUs to keep up with model complexity. Lastly, it seems there is still an opportunity to optimize large model training/retraining and deployment.
OPEN QUESTIONS
Though there is a lot of promise in the space, I’m still thinking through how these markets play out and where value ultimately accrues.
From an investor lens, I’m thinking about a couple questions when looking at companies in the space:
For application companies, how do you build defensibility when using an open-source or third party natural language model? A few potential examples:
Generating unique data (Ex: Gong brings new data online which is not otherwise captured, so they are uniquely positioned to provide the intelligence layer on top of it)
Building deeper into a domain or use case (Ex: ScienceIO has focused on healthcare’s unique data terminology and structure which a generalized model is less optimized for)
Embedding further into a workflow (Ex: Seekout builds automated outreach to candidates which would be cumbersome to set up on a new platform)
For infrastructure companies, what do you think is the ideal tech stack for customers and who do you co-exist with? Given that the AI infrastructure landscape is highly fragmented and also contains a few heavy hitters like Google and Amazon, I think it’s important for startups to think about which players they need to partner or integrate with and which ones they are more directly competing with.
CONCLUSION
There will certainly be new unicorns built across this landscape and I’m excited to see these technologies extend in capability and application. While big tech has a role to play in the development of this ecosystem, I’m excited by the work that is done to makes these technologies more accessible to smaller teams.
If you’re a founder in this space, I’d love to chat about what you’re working on and where you think the opportunities lie ahead.
If you’re someone working on or interested in NLP or AI, I’d love to riff on any trends or share what I’m seeing that seems particularly interesting.
Feel free to reach me at on twitter @nanduanilal or email nanilal@canaan.com!
Thank you to Rayfe Gaspar-Asaoka and Nikhita Gupta for feedback on this piece