
Investing in Data & ML: 2022

As a follow-up to last year's post on the data landscape, I wanted to revisit (1) what’s happening in the market at large and (2) what I think are attractive investment areas across data and ML ecosystem.
State of the Market

The Public Markets get a wake-up call
I think the right place to start to describe what’s happening in the data ecosystem is with Snowflake. After a very successful IPO in 2020, Snowflake and other high-growth tech stocks retained their premium multiples long enough to encourage Confluent, Amplitude, and Samsara to IPO. The party ended in November 2021 and software is now trading right around pre-pandemic levels.

Source: Clouded Judgement
Despite the recent beating that tech stocks have taken, the top data and ML businesses like Snowflake and MongoDB still trade at significant premiums. Because data and AI represent some of the largest TAMs in public markets, they will continue to draw disproportionate investor attention.
Since I last wrote this about a year ago, we’ve seen large IPOs in the space which highlight the increasing digitization of products, customer experience, and operations.

M&A hits record high
2021 was also a record year for global M&A. Microsoft stole the show by acquiring Nuance, the healthcare-focused conversational AI provider, for $20B. Later in the year, they one-upped themselves by announcing they would acquire Activision Blizzard for $69B. Google, Microsoft, and Amazon made a record number of acquisitions last year despite looming concerns around anti-trust. With more venture dollars available and new startup creation at all-time highs, I imagine there will continue to be many buying opportunities for big tech.
It will be interesting to see how Snowflake, Databricks, and other large data players approach M&A. Snowflake Ventures launched at the end of 2020, made several startup investments in 2021, and just announced their plans to acquire Streamlit for $800m. Databricks formed their Ventures team just one year later and just last month, MongoDB announced their venture investment fund. Because these companies sit so centrally within the data stack, I think their ability to execute on investments and M&A could be particularly meaningful. The 142% increase in corporate venture capital last year is further evidence that businesses are leaning into M&A.
Private Markets feeling diluted impact
The private markets followed the public markets' success, but we have yet to see a clear indication that the tide has turned. Crossover funds are trying to trade down valuations, but it still seems to be a founder-friendly environment with plenty of capital available. Last year was a tremendous year for enterprise tech more broadly, but it’s unclear how quickly the tide can turn.
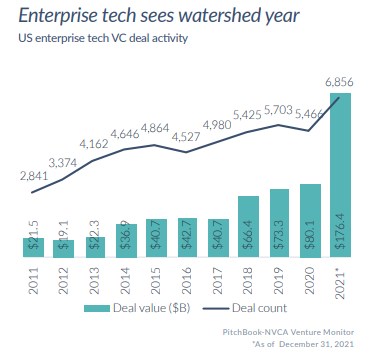
Anecdotally, there have been two types of data/ML companies that have commanded particularly high premiums. First are companies that nail content marketing early on to both efficiently acquire customers and build a strong brand. Fivetran and Monte Carlo have both done this well, and had big markups in 2021. Second are startups that can build strong bottoms-up communities. DBT and Airbyte both have low barriers to adoption with their open source offerings and appear to be nurturing those users into a stronger community. Similarly, both are able to fundraise on the back of that engagement rather than monetization alone.
Investment Themes
Before diving into the specific areas I’m looking at, I want to highlight two reasons that data and ML will continue to be a promising area for investment and company creation:
More businesses are ML-driven and even more, are data-driven. Nearly every business has some type of business intelligence or analytics function today. We are in an earlier shift towards seeing many businesses leverage ML to further improve their decision-making and customer experience.
Data talent demand is growing faster than supply. Lastly, we are seeing nearly every job function requiring a level of data literacy. Data consumers want better tools to understand and analyze data and centralized data teams want better tools to enable the rest of the organization. More on these data jobs later.
Similar to last year, I wanted to outline some high-level themes that I am excited about.
1/ Applications on top of the warehouse
Much of the core data stack is reaching maturity. Large businesses have been built around data movement (Fivetran, Airbyte, etc), data warehousing (Snowflake, Redshift, etc), and data transformation (DBT).
Because data is now centralized and easily movable to different applications, the question becomes what can now do with it? To me, there are two interesting opportunities to shift data further “right” of the warehouse:

First, reverse ETL can supercharge existing SaaS tools. Customers can bring in data outside of that SaaS application via a reverse ETL vendor. For example, bringing in product trial data into your Salesforce app can help identify high-value prospects more easily. Until recently, applications have been limited to the incomplete data they have within their application.
Second, I’m excited about new SaaS businesses building on top of the warehouse. Instead of relying on data only created within the application, there’s now an opportunity to create products that leverage a broader universe of data living in the warehouse. The question I’m looking at is where else are opportunities to improve existing workflows by bringing together disparate data sources? The PLG CRM is one such example, where a category is being created to equip sellers with holistic customer data to improve their sales and expansion efforts.
2/ Scaling Data and ML collaboration internally
Two of the core goals of the modern data stack are to improve accessibility (easier-to-use tools) and to improve scalability (cloud-based). The natural consequence of adopting the modern data stack is that the number and type of data consumers within an organization drastically changes. Benn Stancil describes how this is permeating beyond the traditional “analyst” in his excellent post:
After being exposed to their company’s data, people who we didn’t classify as analysts—and, based on their initial behavior, didn’t classify themselves as analysts either—started to display the same behavioral patterns as analysts.
This creates a variety of collaboration problems that I’ve seen companies try to target from various angles. There are three adjacent categories each focused on a different unit of value – metrics, data, and features. While features are ML-centric and metrics are analytics-centric, they types of questions they seek to answer are similar:

Ultimately, there are a number of collaboration problems that organizations will have to resolve as they embrace a data and ML-driven culture.
3/ Automating Data and ML governance
While one of the problems is data and ML collaboration, there is also the problem of governance. I broadly think of governance products as providing visibility and controls. For visibility, companies need to see which data is sensitive and who is accessing different types of data. For controls, companies need to be able to create and enforce policies easily on who can access what data and for how long. Enabling granular enough controls without creating significant overhead is the ideal solution, which may warrant a governance-as-code solution like we’ve seen in adjacent markets.
On the ML side, most of the above problems are still relevant, but there are additional problems around model fairness and bias. When businesses use black box ML systems to make decisions about consumers, they are privy to bias that is less obvious. Regulatory bodies are already flagging their concerns to businesses especially around financial services. Much like the widespread criticism of companies collecting consumer data, I imagine we may see a similar criticism of companies using biased ML systems. Being able to understand how ML systems are making decisions and proving that they are fair could quickly become a business imperative depending on how regulation moves.
4/ Extending ML to the mid-market
While the “modern data stack” is converging on a handful of main tools, the Machine Learning stack remains fragmented. From data preparation to model training and deployment, there are a number of horizontal platforms and vertical solutions in the space.
There are a couple of reasons for this fragmentation. First, ML is a newer field than business intelligence (which the modern data stack is centered around). Much of the ML tooling that exists today has spun out of large tech companies like Uber and Netflix, which is not necessarily suited for the average enterprise.
Second, and more importantly, ML is a more heterogeneous problem space than BI at the infrastructure layer. The infrastructure needed to build image classification will be different from what’s needed to build conversational AI.
I’m excited about companies that are bundling more of the ML workflow to provide end-to-end products. While Big Tech may prefer to build their tooling in-house, that’s not an option for the broader market.

I think mid-market companies are willing to trade customization for accessibility if it means that they can finally productionize their use cases. I’m excited about companies that can lower the barrier to operationalizing ML and deliver an end-to-end solution.
5/ NLP for everyone
If you haven’t already seen some of the wild things that GPT-3 can do, then stop what you’re doing and check out this app builder, this design tool and an all-in-one sheet formula.
Natural Language Processing (NLP) is concerned with how humans communicate with computers with “normal” language. The better computers become at understanding our queries, the more relevant their outputs. Deep learning models like GPT-3 from OpenAI and BERT from Google are extremely powerful in part because their training sets are incredibly large. As a result, tuning these generalized models to a specific use case requires far less effort than previously. According to a Gradient Flow survey, 60% of leading tech companies indicated their NLP budgets have increased by >10% in the past year as adoption moves beyond just exploration.
In this space, I’m excited by companies that are:
Building or democratizing these models: Given the upfront cost to train these models, model innovation is somewhat constrained to large companies like OpenAI or Google. The more compelling startup opportunity may be to make these models more accessible, collaborative, and shareable.
Leveraging these models for specific use cases: Some companies are choosing use cases where NLP can create entirely new businesses. Given that some of the core technology is not built in-house, these companies are likely to go deeper into the workflows of the problems they solve (copywriting, etc).
Conclusion
While I’m sure that I’ll refine my opinions on these themes, I think they are a helpful starting point for ideas that I am looking for this year. If you’re working on something in this space, I’d love to chat so feel free to drop me a message at nanilal@canaan.com or on twitter at @nanduanilal
nandu